Search Engine
Clarifications/Functional Requirements
- Scope: general search or specialized search? web search or search on social media platform?
- Freshness: real-time search means incorporating trending queries and sources
- Personalization: logged-in user or not, location, search history
Key challenages: maximize relevance while minimize latency
Nonfunctional requirements
- Scale: number of websites? QPS (queries per second)?
Metrics
Online Metrics
- Click-through rate
$$Click through rate = \frac{Number of clicks}{Number of impressions} $$
- Successful session rate
Include the Dwell Time (the length of time a searcher spends viewing a webpage after they’ve clicked a link on a SERP-search engine per page) into consideration.
$$Session success rate = \frac{no. of successful sessions}{no. of total sessions}$$
- Caveat
Attention is to consider zero-click searches. A SEPR may answer the searcher’s query at the top.
Time of success: a low number of queries per session - successful search session.
Offline Metrics
- Normalized discounted cumulative gain (NDCG)
$$CG_p = \sum_{i=1}^{p}rel_i$$
1 | In the cumulative gain, the rel = relevance rating of a document |
$$DCG_p = \sum_{i=1}^{p} \frac{rel_i}{log_2(i+1)}$$
1 | The discounted cumulative gain allows us to penalize the search engines's ranking if highly relevant documents appear lower in the result list. |
Caveat: $DCG$ can’t be used to compare the search engine’s performance across different queries on an absolute scale. (the $DCG$ for a query with a longer result list may be higher due to its length instead of its quality.)
$$NDCG_p = \frac{DCG_p}{IDCG_p}$$ where $IDCG$ is ideal discounted cumulative gain.
1 | NDCG normalizes the DCG in the 0 to 1 score range by dividing the DCG by the max DCG or the IDCG of the query. |
$$NDCG = \frac{\sum_{p=i}^NNDCG_i}{N}$$
An $NCDG$ value near 1 indicates good performance by the search engine.
- Caveat
$NCDG$ does not penalize irrelevant search results.
Architecture
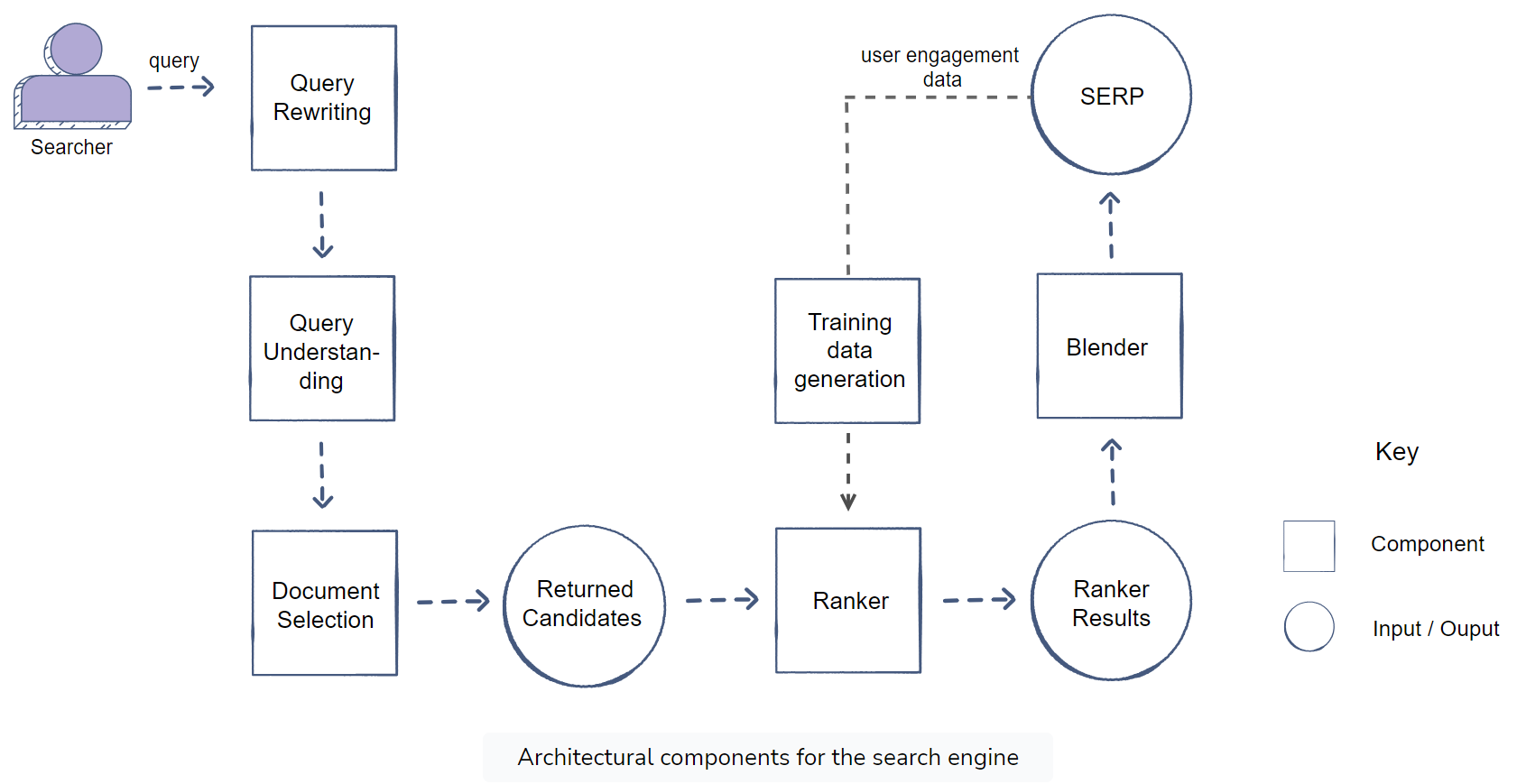
Document Selection
Document selection is more focused on recall.
- Selection criteria
- Inverted index: an index data structure that stores a mapping from content.
- Go into the index and retrieve all the documents based on the above selection criteria. -> sorted relevant documents according to their relevance score. -> forward the top documents to the ranker.
- Relevance scoring scheme
- Weighted linear scheme from:
- Terms match: inverse document frequency or IDF score
- Document popularity
- Query intent match
- Personalization match.
- Weighted linear scheme from:
Training Data Generation
Pointwise approach
- Assign positive/negative samples based on click rate or successful session rate.
- Caveat: Less negative examples. To remedy it, we use random negative examples.
Pairwise approach
- The loss function looks at the scores of document pairs as an inequality instead of the score of a single document.
Feature Engineering
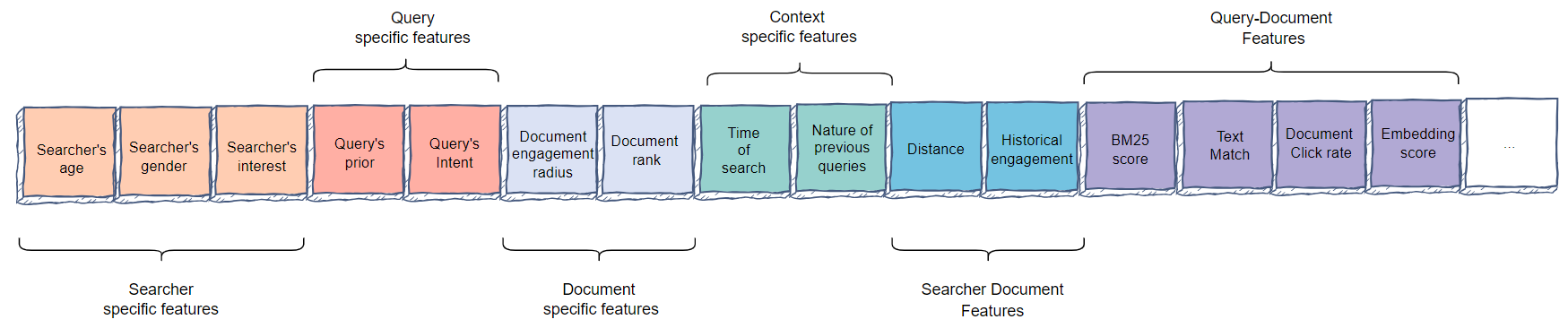
- Query-specific features
- Query historical engagement
- Query intent
- Example: Users search for ‘pizza place’, the intent here is ‘local’.
- Document-specific features
- Page rank
- Document engagement radius
- Context-specific features
- Time of search
- Recent events
- Searcher-document features
- Distance
- Historical engagement
- Query-document features
- Text match
- Unigram or bigram
- TF-IDF (term frequency-inverse document frequency) match score can also be an important relevance signal for the model.
- Query-document historical engagement, like click rate
- Embeddings. To calculate similarity score between the query’s vector and the document’s vector.
Model Development
Search Retrieval
Ranking
Stage-wise approach is being used. First stage will focus on the recall of the 5-10 documents in the first 500 results while the second stage will ensure precision of the top 5-10 relevant documents.
- Stage 1: pointwise approach
- Simple ML algorithms
- Performance: AUC or ROC
- Stage 2: pairwise approach
- LambdaMART
- LambdaRank
Example: Rental Search Ranking
Problem statement:
- Sort results based on the likelihood of booking.
- Build a supervised ML model to predict booking likelihood -> Binary classification model.
Metrics:
- Offline metrics:
- conversion rate: $conversion_rate = \frac{number_of_bookings}{number_of_search_results}$
- Online metrics:
- $DCG$
- $NDCG$
- $IDCG$
- Offline metrics:
Requirements
- Training:
- Imbalance data and clear-cut session
- Train/validation data: Split data by time to mimic production traffic.
- Inference:
- Serving: low latency
- Under-predicting for new listings: not enough data for model to estimate likelihood for brand new listings.
- Training:
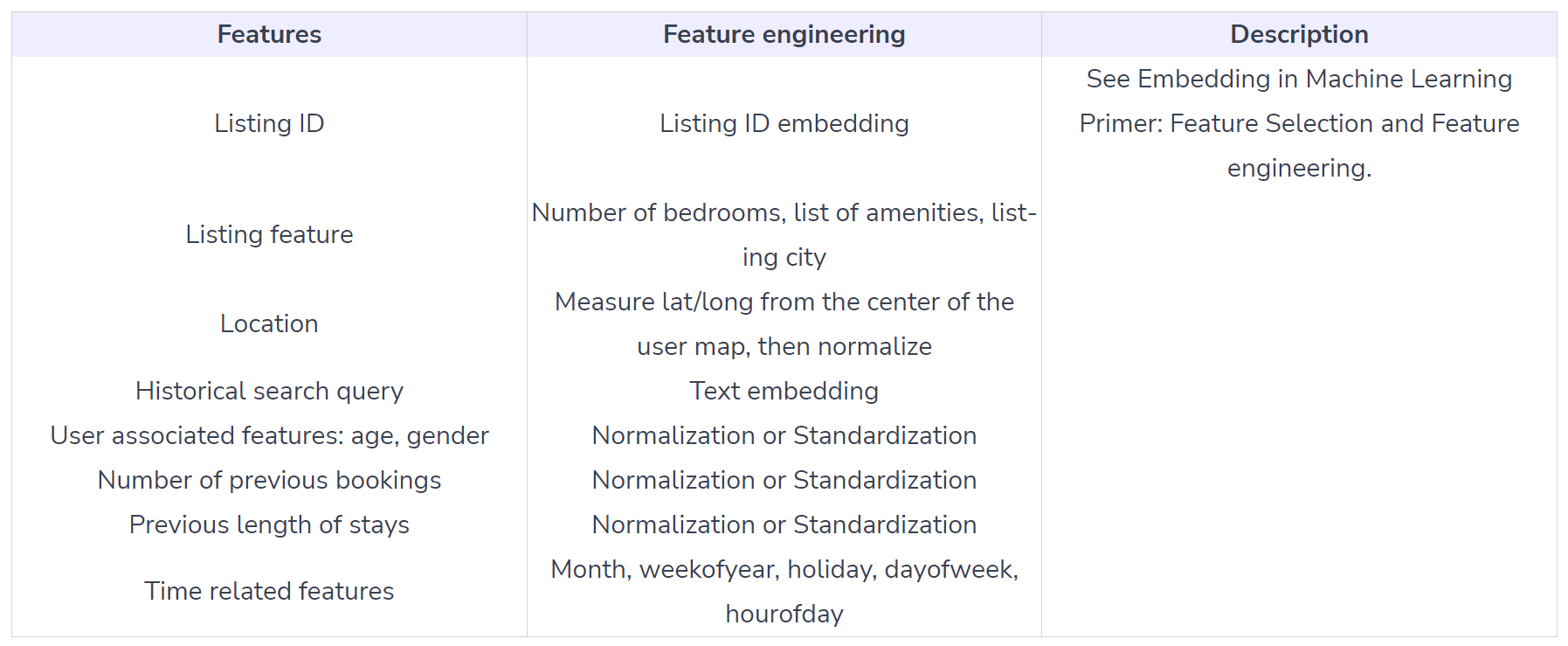
Model
- Feature Engineering
- Geolocation (latitude/longitude): raw data is not smooth, we can use log of distance from the center center.
- Favourite places.
- Train data:
- decide the length of training data by running experiments.
- Model:
- Input: User data, search query, and Listing data.
- Output: binary classification, i.e., booking a rental or not
- fully connected layers as baseline, or more modern architecture (VAE).
- Feature Engineering
Calculation&&Estimation
- Assumptions: $5 * 30 * 10^8 = 1.25 b$ where 5-5 times per year per user, 30-see 30 rentals before booking, and 100m monthly active users.
- Data Size:
- $500 * 1.25 * 10^9$ where each row takes 500 bytes to store.
- Keep the last 6 months or 1 year of data in the data lake, and archive old data in cold storage.
- Scale: Support $150$ million users.
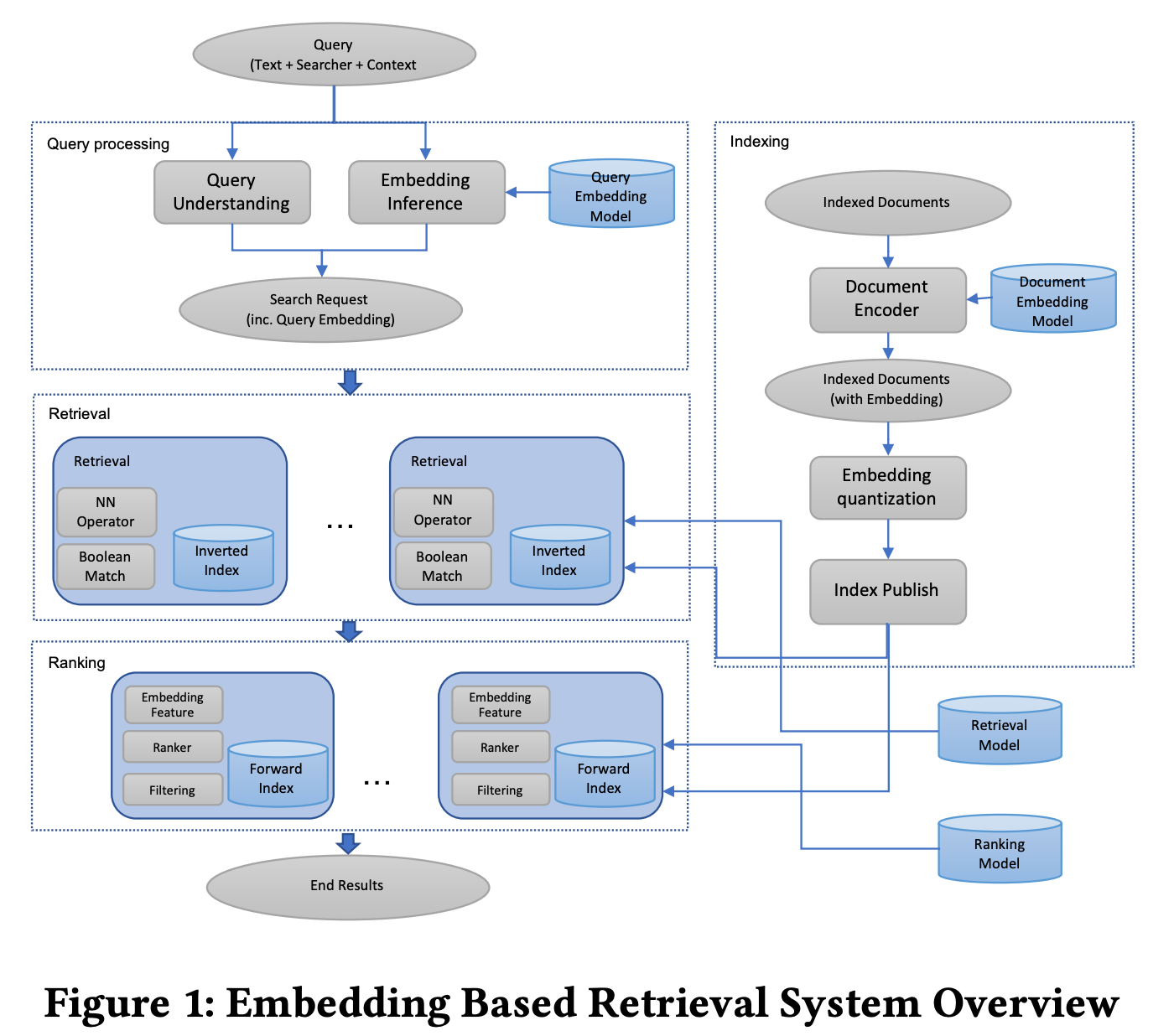
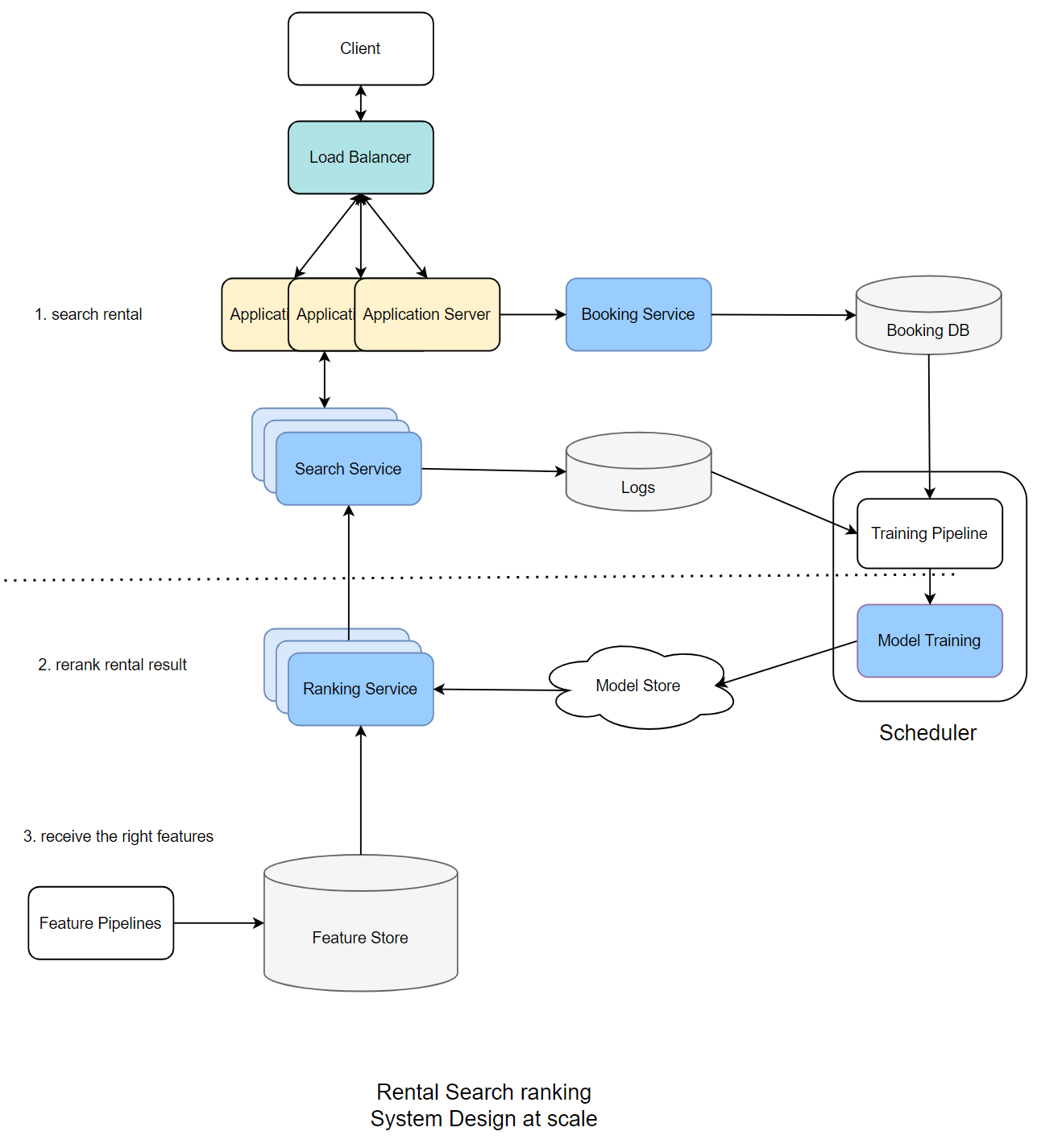
High-level design
- Feature pipeline: Process online features and store key-value feature pairs.
- Feature Store: We need low latency ($<10ms$) during inference: MySQL Cluster, Redis, and DynamoDB.
- To scale and serve millions of requests per second by scaling out Application Servers and use Load Balancers to distribute the load.
- Scale Search/Ranking services.
- Model Store is a distributed storage, like S3.
- Log all candidates as training data which is sent from Search Service to cloud storage or Kafka cluster.
- Follow up Questions
